2025년 3월 멜론이 '방금그곡' 서비스를 종료하면서, 외부 플랫폼에 기댄 인프라의 한계가 드러났다. 국내 지상파 라디오 방송사들은 AI 보이스·제작 자동화 등 핵심 기술을 직접 쥐기 시작했고, 효율과 사람 목소리 사이에서 새로운 균형점을 찾고 있다.
요약문
국내 지상파 라디오 방송사들은 음원 인식, 선곡·추천, 인공지능 보이스, 인공지능 영상, 제작 자동화 등 다섯 가지 기술 축을 중심으로 제작·편성·유통 전반을 재편하고 있다. 2025년 3월 멜론(Melon)의 '방금그곡' 서비스 종료는 방송사들이 핵심 인프라를 외부 플랫폼에 의존했을 때의 구조적 취약성을 드러내며 각사의 자체 개발을 촉진하는 계기가 됐다. 인공지능이 제작 효율화를 견인하는 가운데, 플랫폼의 입지는 좁아지고 오디오 콘텐츠의 경계마저 흐려지고 있는 환경에서, 사람의 목소리와 감성적 연결이라는 라디오 본연의 가치를 어떻게 지켜낼 것인가가 핵심 과제로 부상하고 있다.
1. 들어가며: 인공지능 시대의 라디오, 위기와 실험 사이
생성형 인공지능의 급격한 진화는 방송 산업 전반을 재편하고 있다. 라디오는 가장 오래된 방송 매체이면서도, 인공지능 기술 도입에 있어 빠른 실험의 장 중 하나가 되고 있다. 국내 지상파 라디오 방송사들은 다양한 인공지능 기술을 이미 현업에 적용하거나 적극 검토 중이다.
라디오 광고 시장은 매년 축소되어 전년 대비 감소율이 2023년 15%, 2024년 16.2%에 달했으며, 지상파 라디오 이용률은 2000년 약 58%에서 2025년 17.8%로 떨어졌다. 요즘 차량 이용자들이 주로 소비하는 오디오 콘텐츠는 유튜브(YouTube) 토크 콘텐츠와 팟캐스트, 스포티파이(Spotify)·유튜브 뮤직(YouTube Music)의 음악 실시간 재생 서비스다. 이러한 플랫폼들이 과거 라디오가 독점하던 운전 중 청취 영역을 빠르게 대체하고 있다.
이러한 위기 속에서 인공지능은 두 가지 역할을 동시에 요구받는다. 하나는 제작 비용을 줄이고 효율성을 높이는 도구이고, 다른 하나는 라디오가 경쟁 플랫폼과 차별화할 수 있는 새로운 콘텐츠 실험의 파트너다. KBS, MBC, SBS의 인공지능 활용 사례를 중심으로, 라디오 현장에서 인공지능이 어떻게 쓰이고 있는지, 그리고 어떤 방향으로 나아가야 하는지를 분석하고자 한다.
2. 라디오에 쓰이는 인공지능 기술 개관
라디오 현장에서 활용되는 인공지능 기술은 크게 다섯 가지 축으로 정리할 수 있다. 첫째 음원 인식, 둘째 선곡·추천, 셋째 인공지능 보이스, 넷째 인공지능 영상, 다섯째 제작 자동화다. 각각은 독립적으로 작동하지만, 최근에는 하나의 통합 플랫폼 안에서 유기적으로 연결되는 방향으로 진화하고 있다.
음원 인식(ACR, Automatic Content Recognition)은 방송 중 흘러나오는 음원을 실시간으로 식별하는 기술이다. 음원의 파형에서 고유한 특징값(Audio Fingerprint, Audio DNA)을 추출하고, 이를 사전에 구축된 대규모 음원 데이터베이스의 벡터와 비교해 일치하는 곡을 찾아내는 방식으로 작동한다. 짧은 구간만 들어도 원곡을 식별할 수 있으며, 소음이나 편집이 가해진 음원도 인식 가능하다. 청취자가 '지금 나오는 노래가 무엇인지' 확인할 수 있게 해주는 기본 인프라로, 라디오 앱의 핵심 기능 중 하나다.
선곡·추천은 감성, 분위기, 프로그램 성향에 맞는 음원을 인공지능이 자동으로 추천하거나 재생 목록을 구성하는 기술이며, 저작권 문제가 없는 음원 생성도 포함한다. 음원 자체의 음향적 특성을 분석하는 콘텐츠 기반 방식과 청취 이력·행동 패턴을 학습하는 사용자 데이터 기반 방식이 있으며, 실제 서비스에서는 두 방식을 결합하거나 자연어 프롬프트로 분위기를 입력하는 방식으로 진화하고 있다.
인공지능 보이스는 진행자나 아나운서의 목소리를 학습하여 대본을 자동으로 낭독(Voice Cloning)하거나, 인공지능 캐릭터 목소리를 생성(Text to Speech, 이하 TTS)하는 기술이다. TTS 기반의 라디오 가상 진행자가 여기 포함된다.
인공지능 영상은 라디오 콘텐츠를 원천 자료로 쇼츠(Shorts)·클립(Clip) 등 영상 콘텐츠를 자동 편집·생성하거나, 생성형 인공지능으로 완전히 새로운 영상 콘텐츠를 만들어내는 기술이다. 여기에는 실제 얼굴과 신체를 가진 디지털 캐릭터가 방송을 진행하는 가상 진행자도 포함되는데 디지털 휴먼(Digital Human) 방식의 실시간 상호작용이 포함된다. 이 경우 라디오는 오디오 플랫폼을 벗어나 영상 플랫폼으로 확장된다.
'제작 자동화'는 음성인식(Speech to Text, 이하 STT), 대규모 언어 모델(LLM, Large Language Model, 이하 LLM) 등을 활용해 라디오 제작 과정에서 반복적으로 발생하는 업무를 자동화하는 기술이다. 방송 후 발화자별 대본 자동 생성, 선곡 목록 자동 추출, 타임코드(Timecode) 기반 메타데이터 관리, 광고·음원 편집 자동화, 뉴스 기사 초안 작성 등이 포함된다. 제작자가 반복 작업에서 벗어나 기획과 취재 등 창의적 업무에 집중할 수 있게 하는 것이 핵심 목적이다.
표 1 라디오 인공지능 기술 분류와 국내 방송사 활용 현황
기술 분류
주요 기능
국내 활용 현황
음원 인식 (ACR)
방송 중 음원을 실시간으로 식별하여 선곡표 자동 생성
2025년 3월 멜론 '방금그곡' 서비스 종료에 대응해 방송사 각사 자구책 마련
KBS: 기존 자체 음원 인식 시스템 활용
SBS: 신규 라디오 제작 플랫폼 내의 음원 인식 기능 사용으로 전환
MBC/CBS: 자체 음원 인식 시스템 신규 개발 및 외부 음원 재생 서비스 연동
선곡·추천 (+저작권 프리 음원 생성)
감성·상황 기반 음원 추천, 재생 목록 자동 생성
저작권 무료 배경음악·효과음 자체 생성
SBS (AI MUSIC): 방송사 최초로 PD들이 참여해 1만 곡의 감성 데이터셋(Dataset)을 구축, 160만 곡 추론 및 선곡 지원
MBC (MUSE): 자연어 프롬프트 기반 음원 탐색 및 자체 저작권 확보 가능한 프리 음원 생성 기능 구현
KBS (AI AUDIO): STT 및 RAG(검색-증강 생성, Retrieval-Augmented Generation, 이하 RAG) 기반 선곡 시스템 개발 중
인공지능 보이스 (음성합성/클로닝)
아나운서·진행자 목소리 합성 및 스크립트 자동 낭독
음성 가상 진행자 운용
KBS (TTS HUB): 사내 전 부서의 TTS 수요를 통합·지원하는 내부 시스템
MBC (MSpeak): 사내 범용 시스템. 대본 자동 교열 및 미디어 자산 관리(MAM) 연동 원스톱 워크플로우 구현
SBS (AI VOICE): AI MUSIC 내 통합. 1문장 레퍼런스 음성 기반 인공지능 보이스 생성 및 송출 시스템 전송
※ 음성 버추얼 DJ 프로그램 활용: KBS '제니크', BBS '보리'
인공지능 영상
오디오 소스 기반 쇼츠·클립 영상 자동 편집 및 생성
영상 버추얼 DJ 운용
KBS 청주총국: 레서피 쇼츠 자동화, 故 현철 인공지능 복원 영상, 아이콩(AI-KONG) 챌린지 쇼츠 등, 디지털 휴먼 국책과제 연구중
※ 영상 버추얼 DJ 프로그램 활용: MBC 플레이브(PLAVE) 플레이디오(PL:RADIO) 채널 운영
제작 자동화 (STT/LLM 등)
STT 기반 발화자별 스크립트 자동 생성
타임코드 기반 메타데이터 생성 및 반복적 편집 업무 자동화
SBS: 화자분리 STT 기반 아카이브 대본 생성, 무음구간 자동 페이드 인·아웃(Auto-Trimming) 편집 기능 적용
MBC: 글자 수 기반 재생시간 예측 및 MAM(Media Asset Management) 연동 일괄 처리
KBS: 광고·음원 편집 자동화
3. 국내 지상파 방송사별 인공지능 도입 현황
3-1. KBS: 인공지능 콘텐츠 확장과 제작 인프라 전환 추진
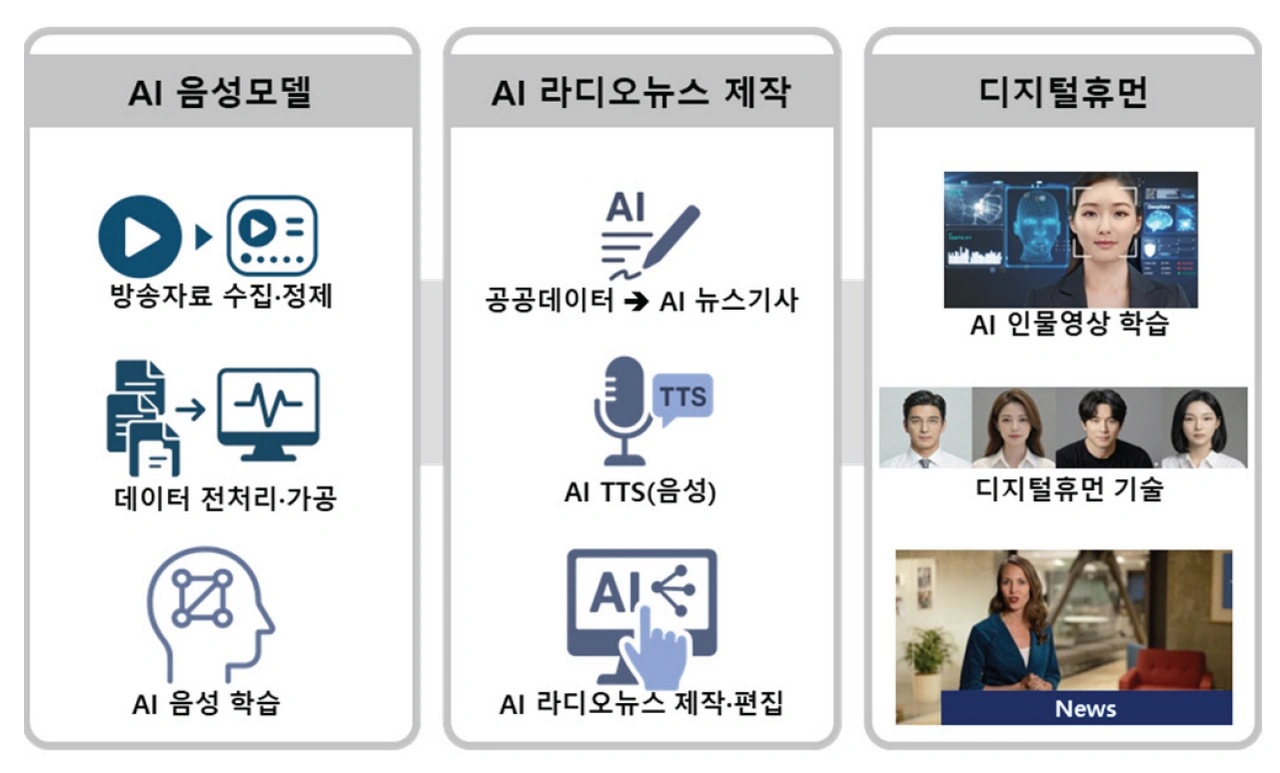
KBS는 2024년 9월, 국내 최초의 생성형 인공지능 라디오 DJ 프로그램 '스테이션 X'를 쿨FM(Cool FM) 채널에 정규 편성했다. 네이버 클라우드의 하이퍼클로바X(HyperCLOVA X) 기반 인공지능 DJ '제니크(Xenique)'는 코너별 프롬프트에 따라 선곡, 원고 작성, 방송 진행 등 라디오 제작 전반에 참여하도록 설계되었다. 인공지능 전문 인력이 아닌 KBS PD들이 클로바 스튜디오(CLOVA Studio)를 활용해 직접 캐릭터를 구현했다는 점이 특징이다. 제니크의 목소리는 클로바 보이스(CLOVA Voice)의 '유나' 음성을 기반으로 속도·음색·감정을 조절하여 제작하고, 클로바 더빙으로 제작되었다.
콘텐츠 실험도 다양하다. KBS 제2라디오(Happy FM)의 '은가은의 빛나는 트로트'는 기획 단계부터 인공지능 기술을 프로그램의 핵심 정체성 중 하나로 녹여내고 있다. 청취자들의 사연을 바탕으로 인공지능이 세상에 하나뿐인 트로트곡을 만들어주는 '빛나는 AI 응원송', 은가은의 목소리를 학습한 'AI 은가은', 현철 1주기를 기념하여 고인의 미발표곡을 'AI 현철'로 재현하여 '듣는 라디오와 보이는 라디오로 송출한 바 있다.
KBS 제1라디오 청주총국 '생생충북'에서는 '우선미의 행복레시피'라는 요리 코너에서도 실험적 시도가 있었다. 방송원고와 음성에서 STT로 텍스트를 추출한 뒤 LLM이 요리 과정에 해당하는 핵심 구간만 선별하여 이를 영상 생성 기술로 연결하는 자동화 파이프라인을 구축했다. 이는 하나의 방송 콘텐츠를 형식에 맞게 자동으로 재가공하는 OSMU(One Source Multi Use) 자동화의 가능성을 보여주는 실험으로, 향후 다양한 장르의 라디오 콘텐츠에 적용 가능한 제작 자동화 모델의 가능성을 보여줬다 할 수 있다.
그림 1 KBS 라디오의 영상생성 자동화 과정
출처 KBS 2025 미디어기술연구보고서 유튜브 채널: '에헤라 티비: KBS LIFE'
보다 시스템적인 접근도 있다. KBS는 2025년부터 한국언론진흥재단 과제로 '인공지능을 활용한 오디오 콘텐츠 제작 효율화 및 데이터 활용 시스템 구축' 사업을 추진하고 있다. 'AI AUDIO'는 외부 클라우드 서비스 기반 설계로 STT 기반 선곡 리스트 자동 추출, 광고·음원 편집 자동화, 타임코드 기반 메타데이터 수집 및 요약, RAG와 LLM 연계 대화형 검색 등 다양한 제작 자동화 통합을 목표로 한다.
KBS는 인공지능을 통합적으로 내부에서 활용하는 방안으로 'KBS TTS 허브' 구축을 추진하고 있다. TTS 허브는 사내 전 부서가 웹서비스 형태로 접근할 수 있으며, 방송자료와 사용자 본인 음성을 활용해 여러 인물의 인공지능 음성을 생성·관리하고, 자체 개발 TTS 모델로 외부 API(Application Programming Interface) 비용 부담과 보안 위험 없이 운용하는 것이 핵심이다. 일반 라디오 제작, 시각장애인을 위한 보이스 뉴스(Voice News), KBS 월드 라디오(KBS World Radio)의 다국어 뉴스 제작 등에 다양하게 활용되어 접근성, 도달율, 그리고 적시성을 동시에 높일 수 있을 것으로 기대된다.
KBS는 뉴스 제작 효율화 차원에서 과학기술정보통신부 과제 '사실적 움직임 생성·재현이 가능한 디지털 휴먼 기술' 연구를 수행 중인데, 실시간 소통이 가능한 디지털 휴먼은 보이는 라디오 등에서 영상형 버추얼 DJ로 활용될 수 있다.
그림 2 KBS 범용 TTS 허브 및 디지털 휴먼 연구
출처 KBS 2025 미디어기술연구보고서
3-2. SBS: 라디오 제작을 위해 통합된 자체 플랫폼
SBS 기술연구소가 자체 개발한 'AI MUSIC'은 국내 방송사 중 가장 먼저 통합된 인공지능 라디오 제작 플랫폼이다. 2023년부터 약 2년에 걸쳐 라디오 PD들과의 긴밀한 소통을 통해 현장 필요에 따라 구축한 시스템으로, 외주 개발 없이 순수 자체 기술력으로 완성했다는 점에서 의미가 크다.
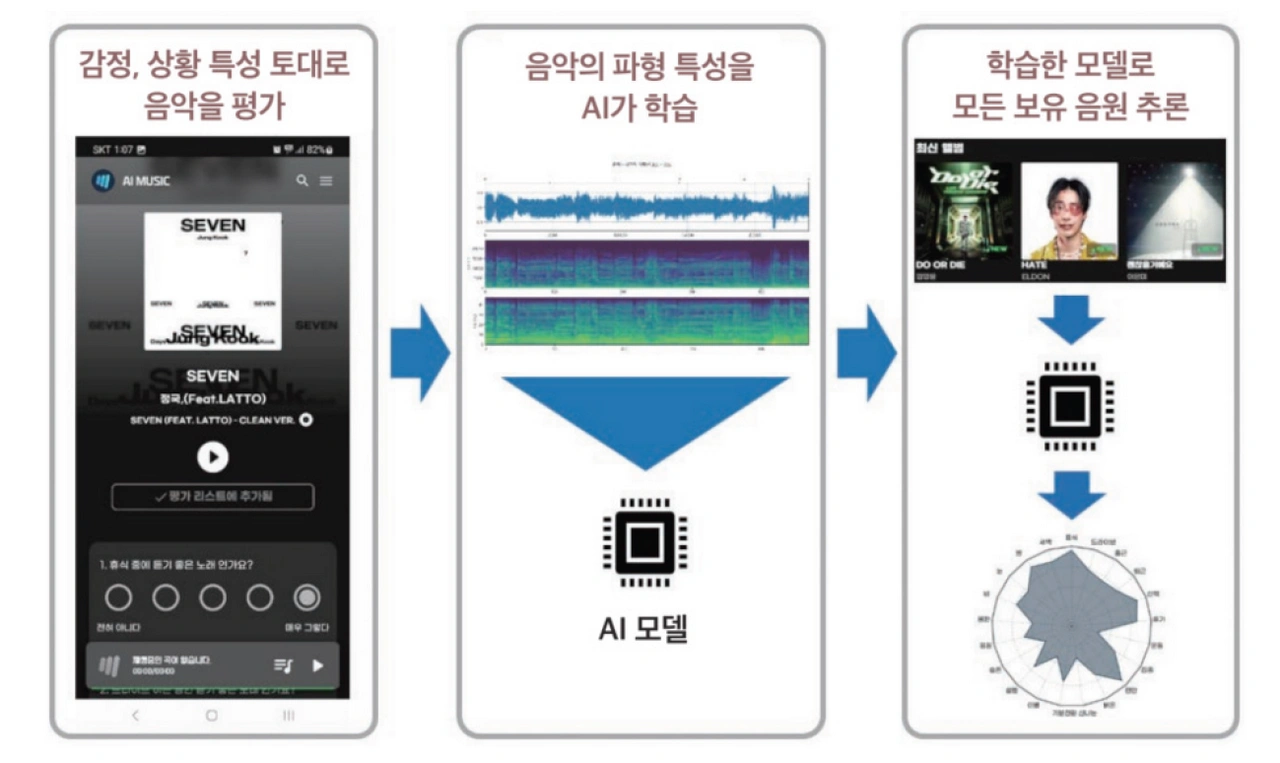
AI MUSIC의 핵심은 자체 선곡 학습 데이터셋이다. SBS 라디오 PD들이 직접 참여하여 약 10,000곡의 음원에 대해 '신나는 곡인가?', '비가 올 때 듣고 싶은 곡인가?' 등 21개 감성·상황 항목을 1점에서 5점으로 평가한 것으로, 방송사 최초로 구축된 자체 선곡 데이터셋이다. 이를 멜스펙트로그램(Mel Spectrogram: 시간-주파수-에너지의 3차원 정보를 2차원 이미지로 표현) 기반 인공지능 모델로 학습시켜 보유한 약 160만 곡의 음원에 대해 21개 항목의 점수를 추론할 수 있게 되었다. 신규 음원이 추가될 때마다 실시간으로 작동하여 즉각적인 선곡 지원이 가능하다.
자체 개발한 '오디오 DNA' 기술은 각 오디오의 고유한 DNA를 임베딩 벡터(Embedding Vector) 방식으로 추출하여 동일하거나 유사한 음원을 식별한다. 이를 통해 기존에 외부 상용 서비스에 의존하던 음원 인식을 내재화하였고, 160만 곡 중 동일 곡의 다양한 버전을 하나의 대표곡으로 그룹화하는 기능도 구현했다.
프리셋 기반의 자동 제작 기능 및 무음 구간을 자동 추출하여 페이드 인/아웃 처리까지 자동화하는 오디오 기술(Auto-Trimming)은 별도 편집 작업을 대폭 줄여 원하는 분량의 방송 제작을 상당 부분 자동화 해준다.
화자분리 STT 기반 아카이브 기능은 방송 후 발화자별로 분리된 대본을 자동 생성하고 기사 형식으로 변환하는 기능이다. 진행자, 출연자 정보가 구조화되어 검색과 콘텐츠 재활용에 활용할 수 있다.
인공지능 보이스 기능은 한 문장 정도의 진행자 음성만으로 TTS를 생성하여 바로 전송하는 방식이다.
SBS AI MUSIC이 주목받는 이유는 단순히 기술 완성도가 아니라, 처음부터 라디오 제작 현장 언어로 설계되었다는 점 때문이다. 선곡 데이터셋은 PD들의 감각이 모델에 이식된 결과이고, 자동화 오디오 기술(Auto-Trimming)은 편집실의 반복 노동을 없애기 위해 만들어졌으며, 화자분리 STT는 방송 아카이브의 실무 문제를 해결하기 위해 설계되었다. 그리고 이 모든 것이 하나의 시스템 안에서 제작부터 송출까지 연결된다. 기술이 현장을 찾아간 것이 아니라, 현장이 기술을 빚어낸 시스템이다.
그림 3 SBS AI MUSIC의 인공지능 선곡용 학습
출처 방송과 기술 2026년 4월호
3-3. MBC: 범용 'AI 보이스'와 라디오 특화 음원 시스템의 분리 설계
MBC IT솔루션팀은 방송 최적화 인공지능 음성 제작 플랫폼 'MSpeak'와 인공지능 기반 통합 음악 검색·음원 생성 시스템 'MUSE'를 개발하여 실무에 적용 중이다. 두 시스템은 각각 음성과 음악 영역을 담당하며, 라디오에 국한되지 않고 사내 전 제작 채널에서 활용가능하도록 설계된 것이 특징이다.
MSpeak에서는 기자나 아나운서의 목소리를 복제하거나 여러 아나운서의 목소리를 학습해 '디자인된 목소리'인 MBC 대표 'AI 보이스'를 만들었다. 고품질 음성 데이터를 학습시켜 발화자 고유의 억양·호흡·발음 습관까지 재현한다. 단순 텍스트 입력을 받아 TTS가 읽기 가장 좋은 형태로 대본을 자동 교열하며, 고유명사·숫자·외국어 발음 규칙을 사전에 처리하여 오독을 최소화한다. 방송 분량 조절을 위해 글자 수를 기반으로 한 예측 시간과 실제 음원 기반의 최종 시간을 함께 제공하는 재생 시간 예측 기능도 갖추고 있다. 단신 기사 한 건의 음원 생성에 약 2~4분이 소요되어 긴급 보도 환경에서도 활용 가능하며, 생성된 음원은 사내 미디어 자산 관리(MAM) 시스템과 직접 연동되어 편성·송출까지 자동으로 이어지는 원스톱 워크플로우를 지원한다. 현재 예능, 디지털 뉴스, 사내 방송 등 다양한 채널에서 실무에 투입되어 운영 중이며, 라디오 뉴스 분야에서도 안정성을 검증받아 도입 범위를 지속적으로 확대하고 있다.
MUSE는 LLM 기반 질문 재작성, 음향적 특성을 반영한 벡터 기반 검색과 정형 데이터 분류 방식을 결합한 하이브리드 방식으로 음원을 탐색한다. '여름 휴양지의 설렘'처럼 추상적인 자연어 프롬프트 만으로도 분위기·감성에 맞는 음원 탐색이 가능하고, 연도·장르·분위기 등 상세 분류로 결과를 직접 조정할 수도 있다. 방송 프로그램 특성에 맞는 재생 목록을 자동 생성하고 제작진이 직접 편집한 뒤, 완료된 목록을 송출 시스템으로 즉시 전송하는 통합된 처리 방식을 보인다. 배경음악·효과음 등 저작권 걱정 없는 음원을 자체 생성하는 기능도 갖추고 있으며, 생성된 모든 음원의 저작권은 MBC에
특성과 갱신 주기가 서로 다르다. 이를 단일 구조로 묶으면 특정 기능 하나가 노후화됐을 때 전체 시스템을 재구축해야 하는 문제가 생긴다. 따라서 외형상 하나의 통합 플랫폼이더라도 내부는 기능별 독립된 단위로 구성하는 것이 바람직하다. 각 단위 안에서는 외부 API, 오픈 소스, 자체 개발을 적절히 조합하는 전략이 필요하다. 외부 API는 빠르게 도입할 수 있지만, 비용 부담과 서비스 지속성 문제가 따른다. 핵심 기능을 외부 API에 전적으로 의존하면 언제든 서비스 단절의 위기가 찾아올 수 있으며 인공지능 서비스 API를 대량으로 호출하면 비용 문제에 직면하게 된다. 반면 공개 자료를 가져다 쓸 때는 초기 구축 비용이 들지만, 지속 운용 비용을 통제할 수 있고 내부 자료 보안도 유지할 수 있다.
인공지능 기술의 발전 속도를 고려하면 교체 가능성이 설계의 핵심 원칙이 되어야 한다. 오늘은 최선의 모델이었지만, 6개월 뒤에는 구식이 될 수 있다. 특정 모델에 시스템이 강하게 결합되면 더 나은 기술이 나와도 교체 비용이 커서 해당 기술을 계속 쓰게 되는 함정에 빠진다. 각 기능 단위가 표준화된 인터페이스(Interface)로 연결되고, 내부 구현은 독립적으로 교체할 수 있는 구조가 이상적이다.
라디오 인공지능 제작시스템의 설계는 기술 선택의 문제이기 이전에 지속 가능성의 문제다. 빠르게 도입하되 오래 쓸 수 있게, 외부기술을 활용하되 핵심은 내재화하게, 지금 최선이되 내일 교체할 수 있도록, 세 가지 원칙의 균형이 방송사 인공지능 인프라의 수명을 결정한다.
4. 음원 인식 인프라 재편과 플랫폼 종속의 교훈
4-1. 멜론 '방금그곡' 종료와 각사의 대응
2025년 3월 31일, 멜론이 '방금그곡' 서비스를 종료했다. 이 서비스는 2016년 말 시작된 이후 약 8년간 운영된 서비스이다. 라디오 방송에 나온 음악을 실시간으로 확인할 수 있는 음원 인식 기반 서비스로, 대부분 방송사 라디오 앱의 선곡표를 제공하는 핵심 인프라이기도 했다. 라디오 선곡표가 멜론 다시 듣기로 바로 연결되어 윈윈(win-win) 전략으로 보이기도 했으나 멜론 측은 사용자 관심 저하 및 운영비 절감의 이유로 서비스를 종료했다. 이는 방송사들이 청취자 접점의 핵심 기능을 외부 플랫폼에 의존할 때의 문제점을 보여주는 사례였다.
SBS는 2023년부터 자체 오디오 DNA 기술을 새로 개발해오던 중이어서 해당 시스템을 사용할 수 있었다. KBS는 10여 년 전 개발해 둔 자체 음원 인식 시스템으로 바로 전환했다. MBC와 CBS도 자체 음원 인식 시스템을 새로 개발했다고 알려져 있다. 방송사들은 음원을 인식한 뒤 선곡표와 각 곡에 대한 메타데이터를 표출한다. 방송사는 저작권법상 전송 권한이 없어 음원 다시 듣기를 위해서는 외부 음원 실시간 재생 플랫폼과의 식별체계 연결을 거쳐 음원 듣기 링크를 제공하기도 한다. 이는 원래 방송된 라디오 프로그램 그대로의 다시 듣기 형태는 아니다.
표 2 국내 주요 방송사 라디오 앱 선곡표 연동 정보
방송사
앱 명칭
선곡표 연동 정보
KBS
콩(KONG)
제목, 가수, 음반 표지
SBS
고릴라
제목, 가수, 음반 표지, 가사
MBC
미니(mini)
제목, 가수, 음반 표지, 가사 선곡표 → 'FLO 다시듣기' 링크 연결
CBS
레인보우
제목, 가수, 음반 표지, 가사 선곡표 → '멜론 다시듣기' 링크 연결
외부 상용 음원 인식 서비스는 점점 저렴해지고 있다. 음원 인식 클라우드(Cloud-based Music Recognition)는 실시간 스트림 모니터링 기준 채널당 월 26달러(약 3만 5천 원) 수준이며, 오디(AudD)는 스트림 당 월 45달러로 24시간 모니터링 서비스를 제공한다. 그 외 그레이스노트(Gracenote, 닐슨 계열), 오디블 매직(Audible Magic) 등이 방송사급 서비스를 제공한다.
4-2. 외부 음원 인식을 안 쓰는 다른 이유와 공동화의 가능성
외부 서비스가 존재함에도 방송사들이 자체 개발을 택하는 이유는 외부 API의 지속 불안 이외에 내부 아카이브 음원 아이디(ID) 연동 문제도 있다. 외부 음원 인식 서비스가 곡을 인식해서 결과를 돌려줘도, 그 결과가 방송사 내부 음원 아카이브의 아이디 체계와 연결되지 않으면 선곡표 자동화는 물론, 후속 인공지능 기능을 구현할 수 없다. 한 방송사가 개발한 음원 인식 기능을 다른 방송사에서 구매하려고 해도 이 문제가 발생한다.
각사가 비슷한 기능을 각자 개발하는 비효율도 문제다. 송출 시스템이 각사마다 다르고 음원 아이디 체계도 달라 완전 통합은 불가능하지만, '통합'이 아닌 '연결'의 관점으로 보면 가능한 영역이 생긴다. ISRC(International Standard Recording Code, 국제 표준 음원 코드)나 Music.UCI(한국저작권위원회가 관리하는 음원 식별 아이디)를 공통 키(key)로 각사 내부 아이디를 연결하고, 공통 키가 없는 음원은 오디오 DNA 같은 파형 기반 식별로 보완하는 방식이다. 감성 분류 데이터셋이나 한국어 TTS 기반 엔진처럼 방송사 공통으로 활용 가능한 레이어는 공동 개발하되, 각사 송출 시스템 연동은 각자가 담당하는 방식을 검토할 만하다. 이른바 '표준화된 인터페이스 위에서의 각자 개발'이다.
5. 커넥티드카 시대의 위기와 통합 플랫폼 전략
5-1. 차량 환경의 변화와 라디오의 위기
라디오 청취의 81.8%가 집중되는 자동차 환경이 커넥티드카 중심으로 급변하며 라디오와 DMB(Digital Multimedia Broadcasting) 같은 기존 매체가 위기에 몰렸다. 국내 차량 내 DMB 수신칩 탑재는 이미 상당히 줄어들었다. 유럽이 동일한 초단파(Very High Frequency, VHF) 주파수 기술을 DAB+(Digital Audio Broadcasting Plus)로 발전시켜 차량 탑재 의무화까지 이뤄낸 것과 달리, 한국은 DMB를 비디오 중심으로 키우다 실시간 재생 플랫폼에 밀려 디지털 라디오 기능까지 함께 잃었다. 이 역사는 향후 차량 내 라디오 수신칩 탑재에서 재현될 위험도 있다.
커넥티드카 환경에서 라디오 수신 방식은 통신망에만 의존하는 실시간 재생 또는 라디오 전파와 통신망을 동시에 사용하는 복합방식으로 수렴하고 있다. 차량에 ATSC 3.0 수신칩이 탑재될 경우에는 방송망과 통신망을 결합하는 보다 다양한 복합 방식도 가능해진다. 하드웨어 탑재 여부가 라디오 생존의 전제 조건이라면, 커넥티드카 대시보드의 앱 구조 안에서 라디오가 어떤 위치를 차지하느냐는 그 다음 조건이다. 탑재되어 있어도 깊은 메뉴 속에 숨어 있으면 청취자에게 닿기 어렵기 때문이다.
한편 차량에서 라디오와 경쟁하는 실시간 재생 앱들은 모든 콘텐츠를 언제든 다시 볼 수 있는 구조라서 요즘 청취자들은 다시듣기 서비스에서 음원이 제공되지 않는 상황을 이해할 수 없어 한다. 일본의 방송사 통합 라디오 플랫폼인 라디코(radiko)는 2010년 일본 전국 방송사들의 참여로 출범하여 스마트폰 앱으로 시작하여 차량 순정 인포테인먼트 시스템 탑재까지 확장해왔다. 라디코는 음원사와 일괄 협상으로 방송 후 1주일간 전체 방송을 그대로 다시 들을 수 있는 타임프리 기능을 구현했는데, 일본에서 라디오 이용률이 오히려 반등한 주요 요인 중 하나로 작용했다.
5-2. K-글로벌 오디오 플랫폼: 분산에서 연합으로
4장에서 살펴본 멜론 '방금그곡' 종료의 교훈은 통합 플랫폼 논의와 직결된다. 방송사들이 음원 인식이라는 핵심 인프라를 외부 플랫폼에 의존하다 하루아침에 위기를 맞은 것처럼, 커넥티드카 시대에 개별 방송사 앱 전략으로는 완성차 업체와의 협상에서 같은 취약성이 반복될 수밖에 없다. 이에 KBS·MBC·SBS·EBS·CBS 5개 방송사와 한국방송통신전파진흥원(KCA)이 주도하는 'K-글로벌 오디오 플랫폼' 구축이 추진 중이다.
통합 플랫폼은 단순한 채널 모음 앱이 아니다. 실시간 재생, 인공지능 기반 개인화 추천, 인공지능 기반 실시간 언어 변환, 디지털 타깃 광고 삽입, 재난 방송 인프라 등의 기능을 포함한다. 무엇보다 방송사들이 한 번도 가져보지 못했던 '청취 데이터 주권'을 확보하는 계기가 된다. 개별 방송사 단위로는 현대·기아차 같은 완성차 업체와 대등한 협상이 불가능하지만, 'K-라디오 연합'으로 하나의 창구를 만들면 유럽 라디오플레이어(Radioplayer)가 협상을 통해 아우디·폭스바겐 그룹 차량 대시보드에 라디오 앱을 탑재하게 되었던 것과 같은 결과를 이끌어낼 수 있다.
통합 플랫폼의 내부 처리 시스템 표준화 작업은 4장에서 논의한 인공지능 제작 인프라 문제와 맞닿아 있다. 각 방송사 자료를 수집하고 메타데이터를 표준화하는 정리 작업이 완성되면, 서로 다른 송출 시스템을 가진 방송사들이 공통 API 레이어를 통해 인공지능 선곡, 추천, 아카이브 서비스를 공유하는 것이 가능해진다. 각사의 내부 음원 아이디 체계는 다르지만, 국제 표준 음원 코드(ISRC) 등의 공통 키로 쓰는 연결 방식을 만들고, 인공지능 생성 등의 이유로 공통 키가 없는 음원은 별도 키로 식별하는 방식을 결합하면 실용적인 공통 레이어 구축이 가능하다. 내부 기능은 각자 개발하더라도 그 결과물을 공통 메타데이터 표준으로 공유하는 구조, 즉 '통합이 아닌 연결'이 현실적인 방향이다.
6. 라디오는 살아남을 수 있을까
6-1. 콘텐츠 경계가 흐려지는 곳에서 기회 찾기
오늘날 차 안에서 라디오와 경쟁하는 것은 유튜브, 스포티파이, 팟캐스트다. 이 플랫폼들에서 소비되는 콘텐츠 상당수는 사실 '귀로 듣는 영상'이다. 운전 중에는 볼 수 없지만 오디오만으로도 충분한 북토크·대담·인터뷰 형식의 영상 콘텐츠들이 차 안에서 광범위하게 소비된다. 유튜브가 팟캐스트 탭을 별도로 만들고, 스포티파이가 팟캐스트에 영상을 추가한 것도 같은 현상을 반영한다. 결국 '라디오냐 영상이냐'라는 구분이 아니라 '귀로 소비되는 콘텐츠'라는 하나의 범주로 수렴하고 있다.
방송사들은 오히려 영상 쪽으로 영토를 확장하려 한다. 방송사들은 보이는 라디오를 자체 앱과 유튜브에서 실시간 재생하고, 각 유튜브 채널에 '귀로 소비되는 콘텐츠' 범주가 아닌 클립 콘텐츠를 올린다. 3.1절에서 소개한 KBS의 인공지능 라디오 영상 사례들은 그 좋은 예이다.
음성 버추얼 DJ와 디지털 휴먼 버추얼 DJ는 이름은 비슷해 보이지만 각각 오디오와 비디오 영역에서 다르게 태어나 서로의 영역을 넘나든다. 'KBS 스테이션 X'의 버추얼 DJ '제니크'와 BBS의 버추얼 DJ '보리'는 TTS 기반 음성 버추얼 DJ로 라디오 본연의 오디오 영역 확장에 해당한다. MBC가 만든 버추얼 아이돌 'PLAVE'는 디지털 휴먼으로 개발되어 공연 등의 영상 플랫폼을 겨냥한 전혀 다른 실험으로 출발했지만, 자체 유튜브 라디오 'PL:RADIO'를 통해 보이는 라디오 형식으로 매주 팬들과 사연 소통을 이어 나갔다.
그림 4 MBC 버추얼 아이돌 PLAVE의 유튜브 라디오 PL:RADIO
출처 유튜브 'PLAVE 플레이브' 채널 영상
영상 확장과는 다른 방향으로, 라디오 앱 자체를 청취 이상의 공간으로 키우려는 시도도 있다. CBS 레인보우 앱의 '함께 걷기' 서비스는 라디오 청취 중에만 걸음이 기록되는 구조로 청취와 건강을 연결하여 출시 첫 달 회원가입자 일 평균 2.8배 증가, 하루 평균 1만 5,666명 참여, 광고 수익 560만 원이라는 성과를 거뒀다. 유튜브나 스포티파이가 쉽게 흉내 내기 어려운 라디오만의 방식으로 40~60대 충성 청취자층을 건강·커뮤니티와 연결한 발상이다. 인공지능으로 만들어낼 수 있는 부가 서비스들은 더 다양할 수 있을 것이다.
6-2. 인공지능은 뒤에서, 사람은 앞에서
인공지능으로 제작된 콘텐츠가 대량으로 쏟아지면서, 역설적으로 인공지능은 혁신이 아니라 저품질로 인식되는 현상이 나타나고 있다. 유튜브는 인공지능 음성으로 위키백과 내용을 읽거나 유사한 형식의 인공지능 영상을 대량 업로드하는 이른바 '인공지능 슬롭(AI slop)' 콘텐츠에 대해 수익 창출을 제한하는 정책을 2025년부터 시행하고 있다. 세계 최대 라디오 네트워크 아이하트 미디어(iHeartMedia)는 소비자의 90%가 인간이 제작한 미디어를 선호한다는 조사 결과를 근거로 'Guaranteed Human' 정책을 공식화하기도 했다.
인공지능 생성 콘텐츠가 넘쳐나는 세상에서 사람들은 오히려 진짜 사람의 온기, 실수, 감정의 떨림을 더 갈망하게 된다. 청취자들이 라디오에 기대하는 것은 DJ의 진심 어린 목소리와 함께 자신의 사연이 소개되는 순간의 특별함이다. 오랜 시간 같은 시간대에 같은 DJ와 함께하는 규칙적 일상, 재난 상황에서 주파수를 틀면 들려오는 안심의 목소리 등은 라디오가 인공지능으로 대체될 수 없는 본질이다. 서비스 확장의 좋은 예로 사용한 CBS 레인보우 앱의 '함께 걷기' 서비스나 관련 이벤트(친구 초대, 색칠하기, 카드 짝맞추기), 네트워크 광고 팝업 등은 다른 관점에서 보면 라디오 청취 편의성을 방해하는 것 처럼 보이기도 한다. 청취자 접점의 확장과 라디오 본연의 편의성이 충돌하지 않는지에 대한 질문은 끊임없이 점검해야 할 과제다.
인공지능은 반복적이고 기계적인 작업에서 탁월한 성과를 낸다. 선곡 목록 검색, 음원 편집, 대본 낭독, 아카이브 정리를 인공지능에 맡기면 PD들은 기획, 연출, 청취자 상호작용 등의 창의적 업무에 더 집중할 수 있다. 인공지능이 뒤에서 일하고 사람은 콘텐츠 앞에 서는 구조가 라디오의 지속 가능한 방향이다.
6-3. 통합 플랫폼과 데이터 주권은 선택이 아니라 생존이다
방송사들은 차량에서 사라지고 있는 DMB 사례를 기억해야 한다. 커넥티드카 시대를 앞두고 방송사들이 단일 대오를 형성하지 않으면 자동차 대시보드에서 라디오는 메뉴 속 점점 더 깊은 곳으로 사라질 것이다. 통합 오디오 플랫폼은 단순한 실시간 재생 서비스 통합이 아니라 세 가지를 동시에 해결할 수 있는 구조다. 완성차 업체와의 협상 창구, 청취 데이터 주권, 그리고 음원사와의 일괄 협상을 통한 온전한 다시 듣기 서비스 실현이다. 통합 플랫폼이 구축되면 실시간 청취 데이터를 기반으로 인공지능 타깃 광고, 개인화 추천, K-오디오 콘텐츠 해외 진출의 기반을 만들 수 있다. 이 모든 과정에서 인공지능은 데이터 분석, 개인화 추천, 번역, 더빙 등의 핵심 역할을 담당한다.
7. 결론
인공지능은 라디오 현장에 이미 깊숙이 들어와 있다. 그러나 인프라와 플랫폼의 대전환 속에서 더 큰 과제들이 남아있다. 커넥티드카 전환으로 위협받는 차량 내 라디오의 입지, 외부 플랫폼 의존으로 드러난 구조적 취약성, 저작권 한계로 인한 다시 듣기 서비스의 경쟁 열위, 그리고 인공지능 콘텐츠 범람 속에서의 정체성 혼란이 동시에 다가오고 있다. 인공지능이 이 모든 과제를 한 번에 해결하는 마법 지팡이는 아니다. 그러나 방송사 연합 통합 오디오 플랫폼 전략과 결합한다면, 인공지능은 라디오가 이 위기를 헤쳐나가는 데 가장 강력한 동반자가 될 수 있다. 플랫폼 확보와 인공지능 기반 제작 효율화 위에서도, 청취자와의 감성적 연결만큼은 결국 인간의 영역으로